



Table of contents
I come from a sysadmin background and I’ve spent many years supporting infrastructures and applications during nights and weekends. Nowadays with Cloud you can easily build solutions that requires little or zero maintenance.
So today I want to talk about how we can implement a Serverless Gitlab runner solution on a AWS ECS Cluster using Fargate. This is the first part where I explain the concept and a diagram that shows how to implement it. Next I will show some code I will post on Github as soon as it’s ready.
What?
Let’s start with a couple of questions: What is a gitlab runner? And What is Fargate?
A Gitlab runner is nothing more that an application that execute Gitlab jobs in pipelines. It gets the code from gitlab and the configuration from .gitlab-ci.yml and execute it. It can be a virtual machine or a docker container. You can use Shared runners provided by Gitlab or host your own runners.
I’m not here to go deep and explain how gitlab pipeline works and how to configure .gitlab-ci.yml, if you are here you probably know already and probably better than me :)
Fargate is an AWS managed service where you can run your ECS or EKS cluster. Being s managed service means that you don’t need to do anything, AWS manages it for you, configuration and patches. In case of ECS what you need is create configurations that are needed by your application to run on the cluster, like memory, cpu, network and the docker image. These configurations are called task definition. Again, you all know how ECS works, right? :)
Why?
After the “What?” there is always the “Why?”. So why we want to build such solution and why on ECS and not on EKS? Good question
Well for start we do it for fun, why not! And second ECS is a bit easier than EKS. ECS is the AWS container orchestrator, it's a proprietary solution. EKS is basically kubernetes on AWS. You don't need to install manually k8s on EC2 instances.
With ECS you just need to configure a task definition and it’s done. It requires less expertise to setup a cluster and run your application.
On the other hand Fargate is the AWS managed compute engine. You don't need to provision any instance, AWS manages it for you. That means less operational overhead of scaling, patching, securing, and managing servers. Fargate is compatible with both ECS and EKS.
Here you can find also how to run “runners” on EKS.
HOW?
Now comes the fun question: how can we build this?
Here’s a diagram
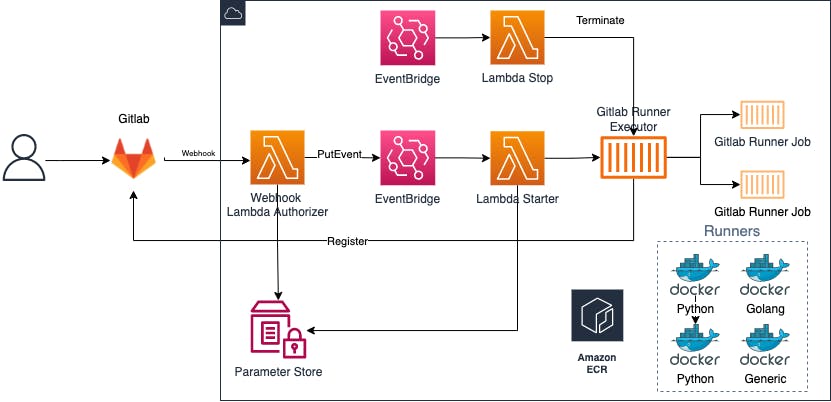
As you can see everything is mainly managed by few lambda functions. But let me explain how the flow works.
What we need is a Docker image for the Gitlab runner executor with Fargate drivers and some other images for the runner jobs which are then executed by the executor.
- First you need to create a webhook in your repository which endpoint is a lambda, passing the token that will be used by the runner to register automatically to gitlab. When you configure the token you pass also the secret that will be used for authentication. Depends on your needs you can pass more parameters in the query strings.
- The webhook lambda authenticates the call against a predefined secrete we have storer in SSM Parameter Store and put an event to EventBridge.
- An EventBridge rule filters the event and call another lambda that will start a runner with Fargate drivers.
- The next lambda get the event from EventBridge, read some parameters from SSM (like the runner token) and check if there are other runners running. If all is good it starts the gitlab runner executor passing the token and few more information.
- The runner register against Gitlab and it's now ready to accept jobs.
- When a new pipeline is triggered the runner starts new jobs in separate containers.
- An event on EventBridge is also scheduled to run every tot time to check if the runner is doing something (if there are jobs running), and if not it will stop the runner to save money.
We’ll go more into the details on part 2 when I’ll show you the code.
The problem
This solution is quite nice, although if you have some complex pipelines it's not perfect as there is a limitation in the taskDefinition that won't allow to override the job image parameter in a pipeline. That means you need bigger Docker images to manage different cases, which is not ideal.
References
docs.gitlab.com/runner/configuration/runner..
Conclusion
I know this solution is not ideal, but I like experimenting and even improve what's already there. I'm sure both Gitlab and AWS will solve the problem of the image soon.
I hope you liked this article and gave you some inspiration and hopefully I can push some code in Github soon to share with you in the next part.
For now thanks for stopping by and reading it and I'm happy to "hear" your thought especially if you have already implemented it.
Ciao!